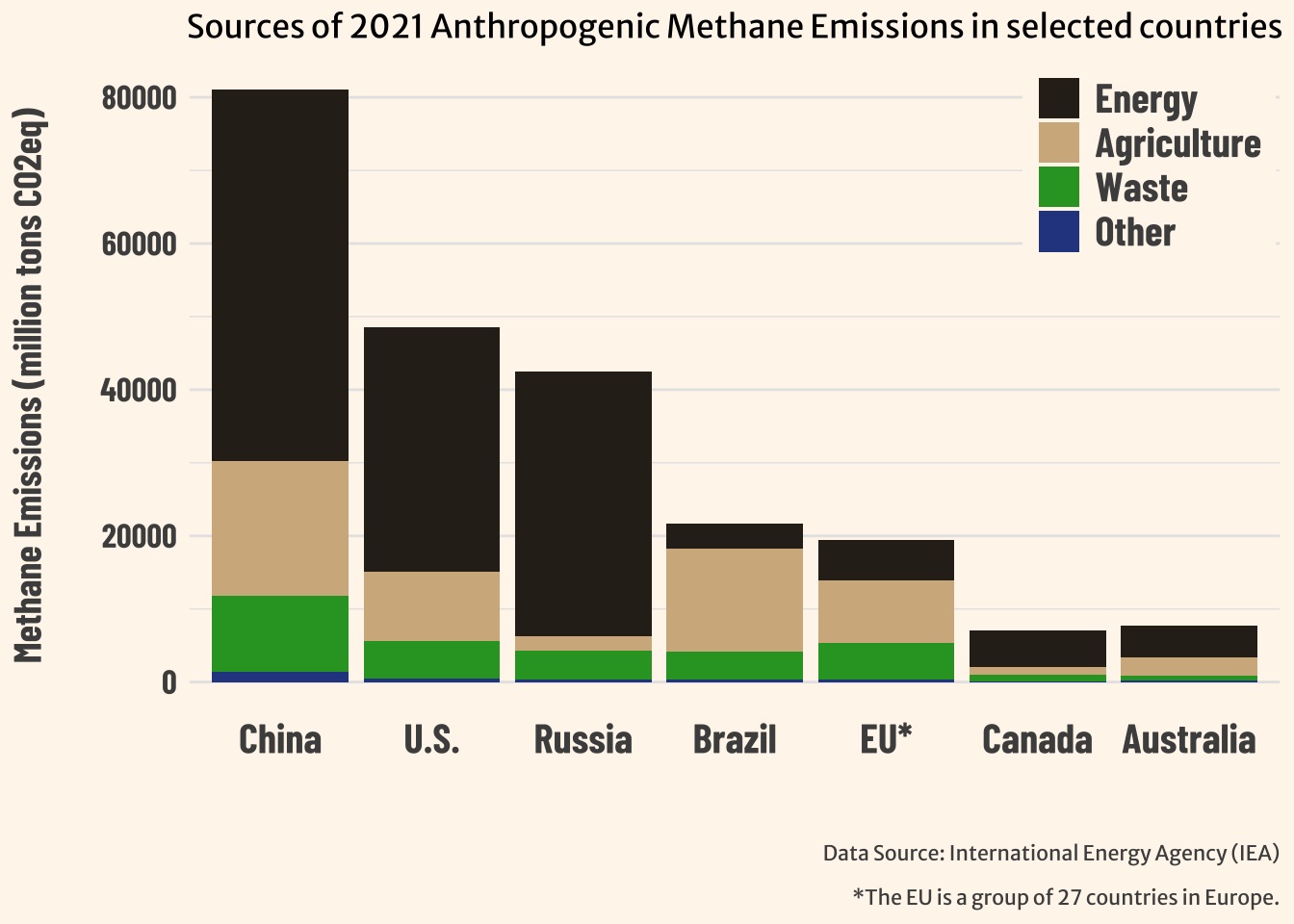
##~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
## plot 2 visualization ----
##~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# create new data frame excluding the countries of focus
other_countries <- scatter_df %>%
filter(!(country %in% c("China", "U.S.", "Russia", "Brazil", "EU*", "Canada", "Australia")))
# create new data frame with countries to label but not highlight (for context)
other_notable_countries <- other_countries %>%
filter(country %in% c("India", "Indonesia", "Iran", "Mexico", "Congo", "Venezuela", "Bangladesh"))
# create new df for just Australia (so can adjust where label is on plot)
australia_df <- scatter_df %>% subset(country == "Australia")
# create new df for highlighted countries minus Australia (so can plot separately)
other_main_countries <- main_countries %>% filter(!(country == "Australia"))
# add new column for alpha values to scatter_df
scatter_df$alpha_value <- ifelse(scatter_df$country %in% c("China", "U.S.", "Russia", "Brazil", "Australia", "Canada", "EU*"), 1, 0.2) # only countries of focus have alpha of 1, all else 0.2
# create scatterplot
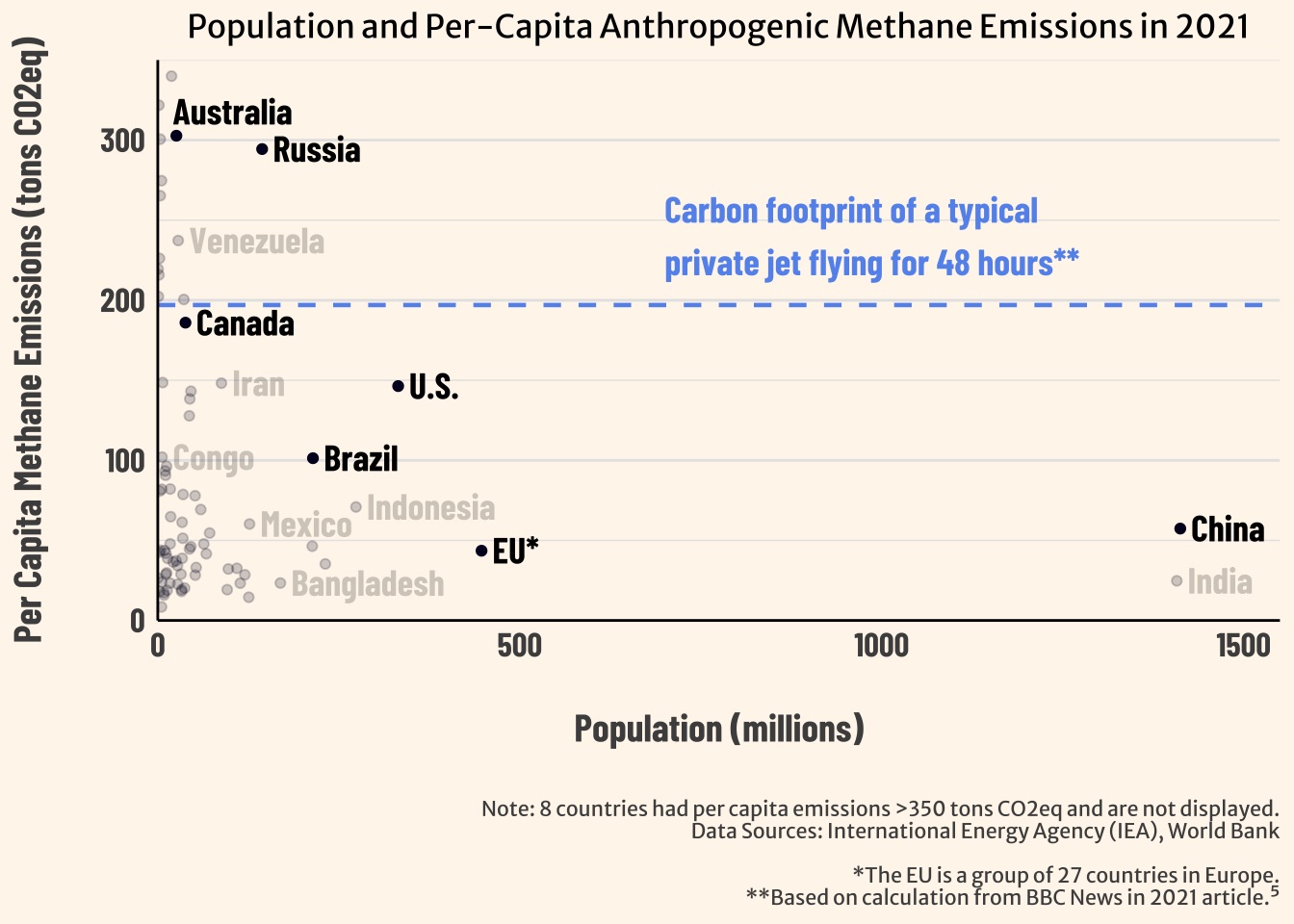
ggplot(scatter_df) +
geom_point(aes(x = population, y = emissions_pc, alpha = alpha_value), color = "#020122") + # use alpha values from the column
scale_alpha_identity() + # tell ggplot to use the alpha values as given (without scaling)
geom_text(data = australia_df, # add text for Australia
aes(label = country, x = population - 5, y = emissions_pc + 15), # position text so does not overlap
size = 5, hjust = 0, family = "barlow", fontface = "bold", check_overlap = TRUE) + # adjust other text features
geom_text(data = other_main_countries, # add text for other main countries
aes(label = country, x = population + 15, y = emissions_pc), # position text
size = 5, hjust = 0, family = "barlow", fontface = "bold", check_overlap = TRUE) + # adjust other text features
geom_text(data = other_notable_countries, # add text for other countries to label
aes(label = country, x = population + 15, y = emissions_pc), # position text
alpha = 0.2, size = 5, hjust = 0, family = "barlow", fontface = "bold", check_overlap = TRUE) + # adjust other text features
labs(x = "Population (millions)",
y = "Per Capita Methane Emissions (tons CO2eq)",
title = "Population and Per-Capita Anthropogenic Methane Emissions in 2021",
caption = "Note: 8 countries had per capita emissions >350 tons CO2eq and are not displayed.\nData Sources: International Energy Agency (IEA), World Bank\n\n*The EU is a group of 27 countries in Europe.\n**Based on calculation from BBC News in 2021 article.⁵") +
scale_x_continuous(limits = c(0, 1550), expand = c(0, 0)) + # set limits on min/max x axis values, use expand to tell to have where two axis meet as origin point
scale_y_continuous(limits = c(0, 350), expand = c(0, 0)) + # set limits on min/max y axis values, use expand to tell to have where two axis meet as origin point
theme_minimal() +
theme(panel.grid.major.x = element_blank(), panel.grid.minor = element_blank(),
axis.title.x = element_text(family = "barlow", face = "bold", size = 15, color = "grey30", # adjust text features for x axis title
margin = margin(20, 0, 0, 0)), # set margin
axis.title.y = element_text(family = "barlow", face = "bold", size = 15, color = "grey30", # adjust text features for y axis title
margin = margin(0, 20, 0, 0)), # set margin
panel.grid.major.y = element_line(color = "grey90", size = 0.5), # add horizontal gridlines (major)
panel.grid.minor.y = element_line(color = "grey90", size = 0.25), # add horizontal gridlines (minor)
axis.text.x = element_text(family = "barlow", face = "bold", size = 13), # adjust x axis text
axis.text.y = element_text(family = "barlow", face = "bold", size = 13), # adjust y axis text
axis.line = element_line(color = "black", size = 0.5), # adjust color and size of axis lines
plot.title = element_text(family = "merri sans", size = 12.5, hjust = 0.5), # adjust plot title text
plot.caption = element_text(hjust = 1, size = 8, color = "grey30", family = "merri sans", # adjust caption text
margin = margin(20, 0, 0, 0)), # set margin
plot.background = element_rect(fill = "#FEF6EC", color = NA), # set plot background
panel.background = element_rect(fill = "#FEF6EC", color = NA)) + # set panel background
geom_hline(yintercept = 197, linetype = "dashed", linewidth = 0.8, color = "cornflowerblue") + # add dashed horizontal line at y = 197
annotate("text", x = 700, y = 240, # position text annotation
label = "Carbon footprint of a typical\nprivate jet flying for 48 hours**",
size = 5, hjust = 0, color = "cornflowerblue", family = "barlow", fontface = "bold") # adjust text features